背景:某分类任务用到了两层(单向)RNN,训练时基于Pytorch中nn.RNN(),C化部署时则需要自己手动实现
RNN
Pytorch中RNN迭代公式如下
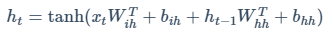
$x_t$为输入,$h_{t-1}$为隐变量
可以看出$h_t$其实就是$x_t$和$h_{t-1}$分别经过线性层,因此可以用两个nn.Linear()实现
以2层单向RNN为例,基于pytorch的rnn分类器以及自我实现如下
class RnnClassifier(nn.Module):
def __init__(self, in_c, hid_c, n_layer = 2):
super(RnnClassifier, self).__init__()
self.rnn = nn.RNN(input_size = in_c, hidden_size = hid_c, num_layers = n_layer)
self.classifier = nn.Sequential(
nn.Linear(hid_c, 1),
nn.Sigmoid()
)
def forward(self, x, hn = None):
''' x: (T,B,in_c)
hn: (2,B,hid_c)
'''
x, hn = self.rnn(x, hn)
x = self.classifier(x[-1, :, :])
return x, hn.detach()
class MyRnnClassifier(nn.Module):
def __init__(self, in_c, hid_c):
super(MyRnnClassifier, self).__init__()
self.hid_c = hid_c
self.Wih0 = nn.Linear(in_c, hid_c)
self.Whh0 = nn.Linear(hid_c, hid_c)
self.Wih1 = nn.Linear(hid_c, hid_c)
self.Whh1 = nn.Linear(hid_c, hid_c)
self.classifier = nn.Sequential(
nn.Linear(hid_c, 1),
nn.Sigmoid()
)
self.tanh = nn.Tanh()
def forward(self, x, hn = None):
if x.dim() == 3:
x = x.squeeze(0)
if hn is None:
hn = torch.zeros(2, x.shape[0], self.hid_c, dtype = x.dtype, device = x.device)
# 2-layer rnn
hn0 = self.tanh(self.Wih0(x) + self.Whh0(hn[0]))
hn1 = self.tanh(self.Wih1(hn0) + self.Whh1(hn[1]))
x = self.classifier(hn1)
hn = torch.stack([hn0, hn1], dim = 0).detach()
return x, hn
def copy_params_rnn(_from, _to):
_dict = {}
for k, v in _from.state_dict().items():
if 'classifier' not in k:
wei, name, num = k.split('.')[1].split('_')
k_new = f'W{name}{num[1]}.{wei}'
_dict[k_new] = v
else:
_dict[k] = v
_to.load_state_dict(_dict)
return _to基于nn.RNN()进行模型训练,完成后将pth文件中的权重字典转成基于nn.Linear()的自我实现形式,可以验证输出严格对齐
LSTM
与RNN类似,LSTM也可以自我实现,公式如下
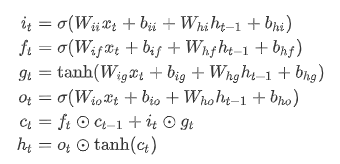
LSTM比RNN多几个gate,因此单层LSTM的自我实现需要用到8个nn.Linear()
class LstmClassifier(nn.Module):
def __init__(self, in_c, hid_c, n_layer = 1):
super(LstmClassifier, self).__init__()
self.lstm = nn.LSTM(input_size = in_c, hidden_size = hid_c, num_layers = n_layer)
self.classifier = nn.Sequential(
nn.Linear(hid_c, 1),
nn.Sigmoid()
)
def forward(self, x, hn = None):
''' x: (T,B,in_c)
hn: (2,B,hid_c)
'''
x, hn = self.lstm(x, hn)
x = self.classifier(x[-1, :, :])
return x, hn
class MyLstmClassifier(nn.Module):
def __init__(self, in_c, hid_c):
super(MyLstmClassifier, self).__init__()
self.hid_c = hid_c
self.Wii = nn.Linear(in_c, hid_c)
self.Wif = nn.Linear(in_c, hid_c)
self.Wig = nn.Linear(in_c, hid_c)
self.Wio = nn.Linear(in_c, hid_c)
self.Whi = nn.Linear(hid_c, hid_c)
self.Whf = nn.Linear(hid_c, hid_c)
self.Whg = nn.Linear(hid_c, hid_c)
self.Who = nn.Linear(hid_c, hid_c)
self.classifier = nn.Sequential(
nn.Linear(hid_c, 1),
nn.Sigmoid()
)
self.sigmoid = nn.Sigmoid()
self.tanh = nn.Tanh()
def forward(self, x, state = None):
if x.dim() == 3:
x = x.squeeze(0)
if state is None:
ht = torch.zeros(x.shape[0], self.hid_c, dtype = x.dtype, device = x.device)
ct = torch.zeros(x.shape[0], self.hid_c, dtype = x.dtype, device = x.device)
state = (ht, ct)
ht, ct = state
# lstm
it = self.sigmoid(self.Wii(x) + self.Whi(ht))
ft = self.sigmoid(self.Wif(x) + self.Whf(ht))
gt = self.tanh(self.Wig(x) + self.Whg(ht))
ot = self.sigmoid(self.Wio(x) + self.Who(ht))
ct = ft * ct + it * gt
ht = ot * self.tanh(ct)
x = self.classifier(ht)
return x, (ht.detach(), ct.detach())
def copy_params_lstm(_from, _to):
_dict = {}
for k, v in _from.state_dict().items():
if '_ih_' in k or '_hh_' in k:
hid_each = v.shape[0] // 4
wei, name, _ = k.split('.')[1].split('_')
# lstm的权重存在一起
_dict[f'W{name[0]}i.{wei}'] = v[:hid_each]
_dict[f'W{name[0]}f.{wei}'] = v[hid_each : hid_each*2]
_dict[f'W{name[0]}g.{wei}'] = v[hid_each * 2 : hid_each * 3]
_dict[f'W{name[0]}o.{wei}'] = v[hid_each * 3 :]
else:
_dict[k] = v
_to.load_state_dict(_dict)
return _to测试
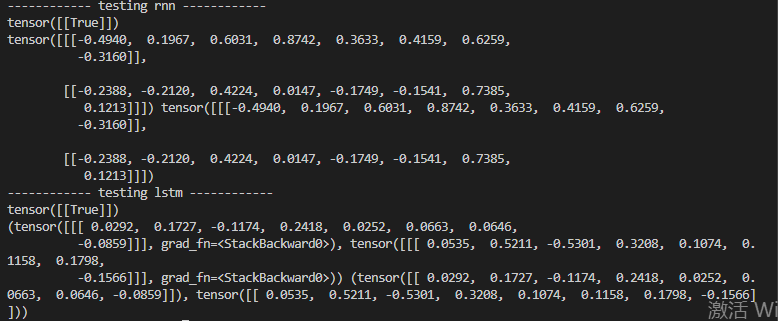
if __name__ == '__main__':
x = torch.randn(1, 1, 4) # (T,B,in_c)
print('------------ testing rnn ------------')
Rnn = RnnClassifier(in_c = 4, hid_c = 8)
MyRnn = MyRnnClassifier(in_c = 4, hid_c = 8)
MyRnn = copy_params_rnn(Rnn, MyRnn)
y1, state1 = Rnn(x)
y2, state2 = MyRnn(x)
print(y1 == y2)
print(state1, state2)
print('------------ testing lstm ------------')
Rnn = LstmClassifier(in_c = 4, hid_c = 8)
MyRnn = MyLstmClassifier(in_c = 4, hid_c = 8)
MyRnn = copy_params_lstm(Rnn, MyRnn)
y1, state1 = Rnn(x)
y2, state2 = MyRnn(x)
print(y1 == y2)
print(state1, state2)可以看出结果严格对齐